如今的小说阅读软件总是在不断的添加广告 如今的小说阅读软件总是在不断的添加广告版app是一款专门为小说爱好者打造的手机阅读软件,这款软件提供了多种类型的小说资源,包括言情、玄幻、都市、穿越等各种题材。而且还支持离线下载和本地缓存功能,方便用户随时随地畅享小说内容。此外,用户还可以根据自己的喜好进行个性化的推荐设置,发现更多感兴趣的作品。
软件特色
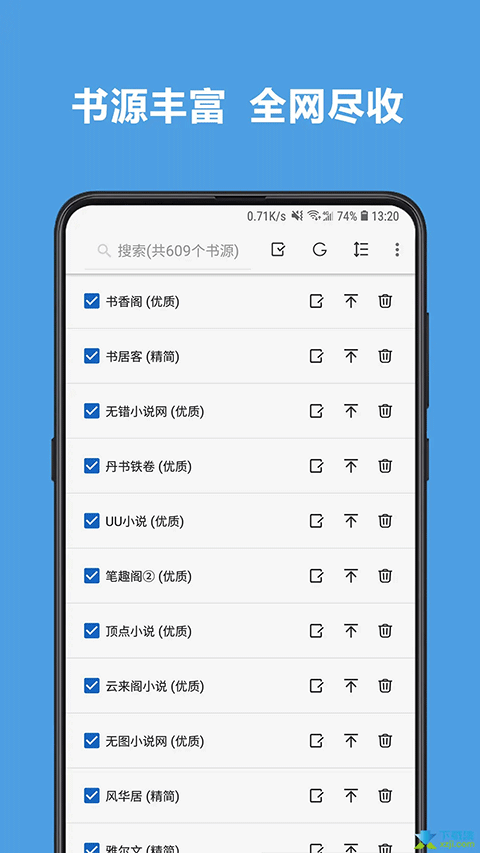
涵盖了众多小说资源,无论你是小说迷还是文学爱好者,都能在这里找到心仪的内容。
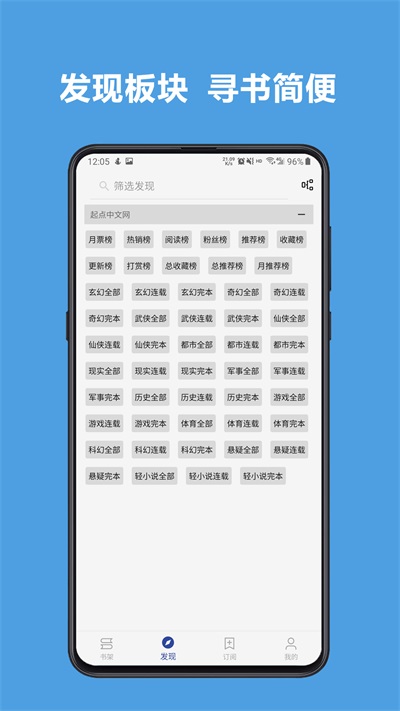
将所有热门小说按照类型整理归类,让您可以轻松浏览自己感兴趣的小说作品,省去了查找的时间。
第一时间获取最新章节,确保您不会错过任何精彩内容。
操作界面简洁明了,即使是初次使用的用户也能快速上手,享受顺畅的阅读体验。
内置精选榜单,帮助您发现更多优质作品,提升阅读效率。
与其他读者交流评论,共同探索未知的阅读世界。
提供舒适的阅读环境,保护您的眼睛,让您更专注于阅读。
调整字体大小、背景颜色等选项,让您的阅读更加舒适。
自动保存用户的阅读记录,并提醒您继续阅读,保持阅读连贯性。
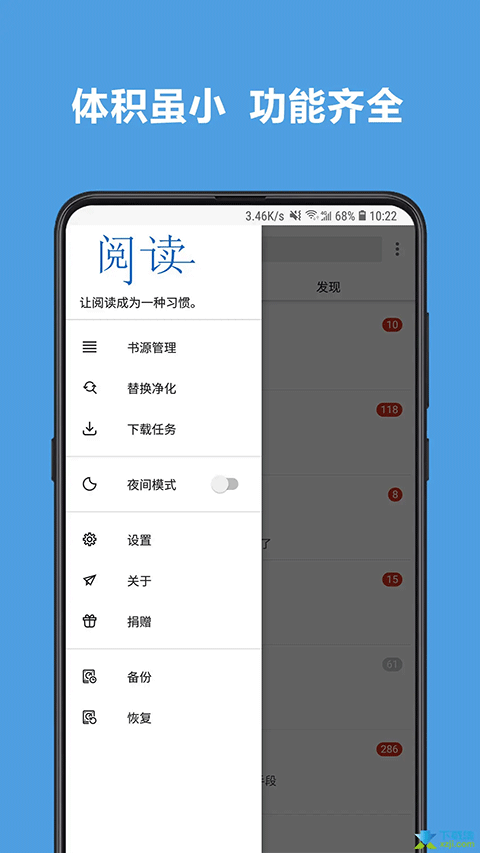
功能介绍
【海量小说】:拥有庞大的小说库,覆盖各类题材和风格,满足用户不同口味的阅读需求。
【高清音质】:提供高品质的语音朗读服务,让听书体验更加生动有趣。
【云端同步】:支持账号登陆,实现跨设备无缝切换,同时还能自由选择阅读进度。
软件亮点
汇集了大量优质图书,涵盖玄幻、历史、奇幻等多个领域,让你尽情享受阅读的乐趣。
设有讨论区,你可以加入喜欢的小说讨论,与志同道合的阅读者一起讨论故事情节。
支持多平台运行,无论是iOS还是安卓,都能获得一致的使用体验。
不断引入新的小说章节目录和新章节,确保每位读者都能紧跟阅读的潮流。



























共有 0条评论